AWS 람다(Lambda) 튜토리얼(3): 계층(Layer) 추가 및 판다스(Pandas) 사용 방법
TABLE OF CONTENTS
1. 서론
저번 아티클에서는 AWS Lambda를 사용하여 데이터 크롤링 프로그램을 구현하는 데 필요한 중요한 설정들, 즉 환경 변수 설정, IAM 역할에 권한 추가, 그리고 타임아웃 및 메모리 설정에 대해 자세히 살펴보았다. 이 아티클에서는 AWS Lambda의 계층(Layer)에 대해 살펴볼 것이다.
AWS Lambda에서 계층(Layer) 기능은 코드 재사용성과 효율적인 라이브러리 관리를 가능하게 해준다. 이번 아티클에서는 계층을 추가하는 방법과, 판다스(Pandas) 라이브러리를 Lambda 함수에 통합하는 과정을 자세히 살펴볼 것이다. 특히, Keith Rozario의 'Klayers' 프로젝트를 활용하여 판다스를 쉽게 사용하는 방법에 대해 설명할 예정이다.
2. 크롤링 및 데이터 적재 예제 코드
저번 아티클에서도 소개한 예제 코드를 동일하게 사용한다. Lambda에서 실행할 수 있는 간단한 Python 크롤링 및 데이터 저장 예제 코드이다. 이 코드는 웹페이지의 데이터를 크롤링하여 AWS S3 버킷에 저장하는 기능을 수행한다:
import boto3
import requests
from bs4 import BeautifulSoup
import pandas as pd
s3 = boto3.client("s3")
def crawl_data(url):
res = requests.get(url)
soup = BeautifulSoup(res.content, "html.parser")
# 여기에 크롤링 로직을 구현
df = pd.DataFrame(...) # 크롤링 결과를 데이터프레임으로 변환
return df
def save_to_s3(df, bucket, key):
csv_buffer = df.to_csv(index=False).encode()
s3.put_object(Body=csv_buffer, Bucket=bucket, Key=key)
def lambda_handler(event, context):
url = "여기에 크롤링할 URL을 입력"
df = crawl_data(url)
bucket = "여기에 S3 버킷 이름을 입력"
key = "여기에 S3 객체 키를 입력"
save_to_s3(df, bucket, key)
return {
'statusCode': 200,
'body': json.dumps('Data successfully scraped and saved to S3')
}
이 코드는 크롤링할 URL에서 데이터를 가져와 DataFrame으로 변환한 후, 지정된 S3 버킷에 CSV 파일 형태로 저장한다. 이 예제를 통해 Lambda에서 Python을 사용한 크롤링과 S3와의 데이터 연동을 실습할 수 있다. 이제 이 코드를 기반으로 Lambda에서의 계층 추가에 대해 알아볼 것이다.
3. 계층(Layer) 추가
Lambda 함수에서 공통적으로 사용될 수 있는 코드, 라이브러리 및 리소스를 계층으로 구성하여 관리할 수 있다. 이는 코드의 재사용성을 높이고, 관리를 용이하게 한다. Lambda에서 외부 라이브러리를 사용하기 위해서는 반드시 계층을 통해야만 한다.
3.1 필요한 모듈 준비
먼저, Lambda에서 직접 사용할 수 없는 라이브러리들, 예를 들어 pandas, requests, bs4 등을 준비해야한다. 근데 Lambda에서는 우리가 로컬에서 사용하는 pandas를 그대로 사용할 수 없다. 다행히 방법이 있으니 필요한 모듈을 모두 준비한 뒤 다시 알아볼 것이다.
3.1.1 python 폴더 생성 및 라이브러리 설치
python이라는 이름의 빈 폴더를 생성한다. 파이썬 런타임을 가진 Lambda에서 계층을 위한 폴더명은 반드시 python이어야 한다:
$ mkdir python
판다스를 제외한 나머지 라이브러리들을 설치한다:
$ pip install -t python requests bs4 # python 폴더에 requests와 bs4 라이브러리 설치
cd python으로 폴더에 접근한 후, 불필요한 파일들을 제거한다:
$ cd python
python$ rm -r *.dist-info __pycache__
python$ cd ..
$
3.1.2 모듈 폴더 압축
python 폴더를 압축하여 python.zip 파일을 생성한다:
$ zip -r python.zip python
3.2 Lambda 계층 생성 및 업로드
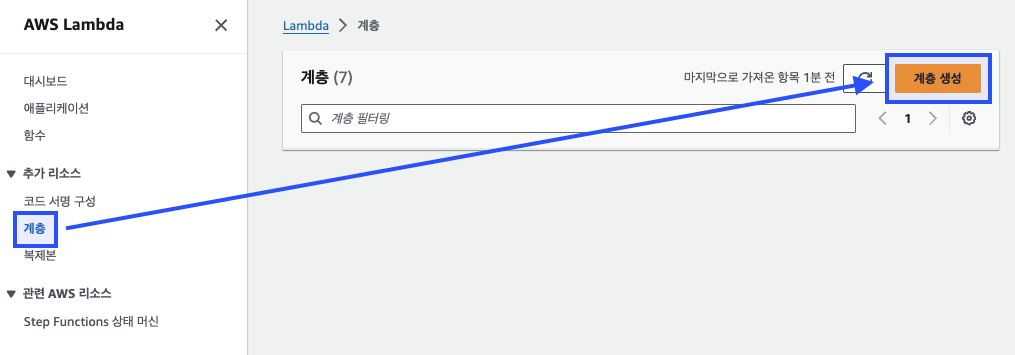
Lambda의 "계층(Layer)" 탭에서 "계층 생성(Create layer)" 버튼을 클릭한다.
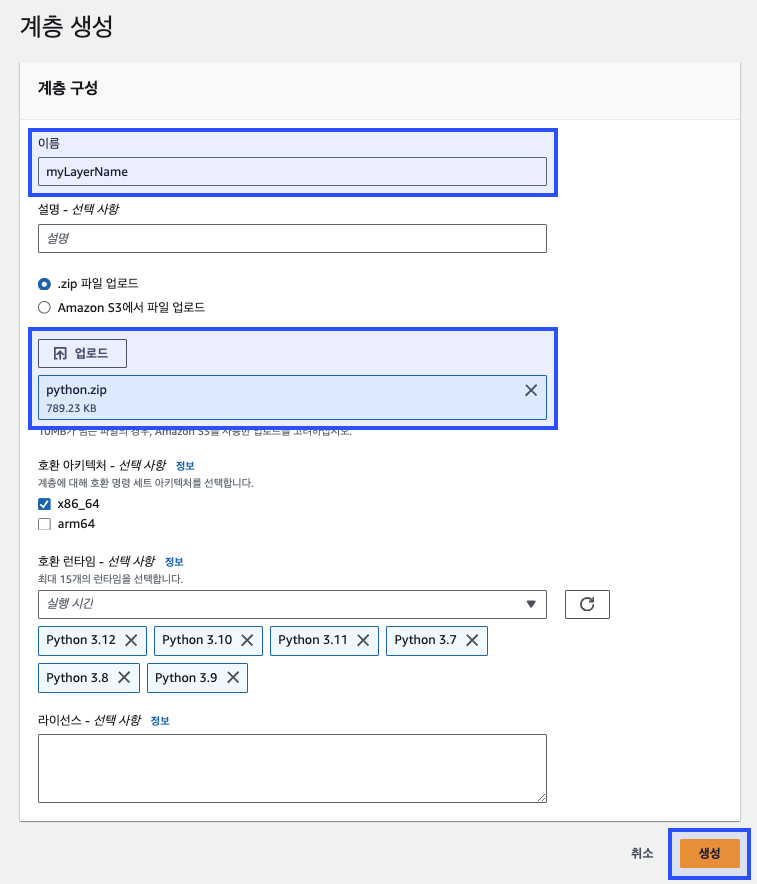
생성 화면에서 이름을 지정하고, 앞서 준비한 python.zip 파일을 업로드한다. 모든 정보를 입력한 후 "생성(Create)" 버튼을 클릭하여 계층을 만든다.
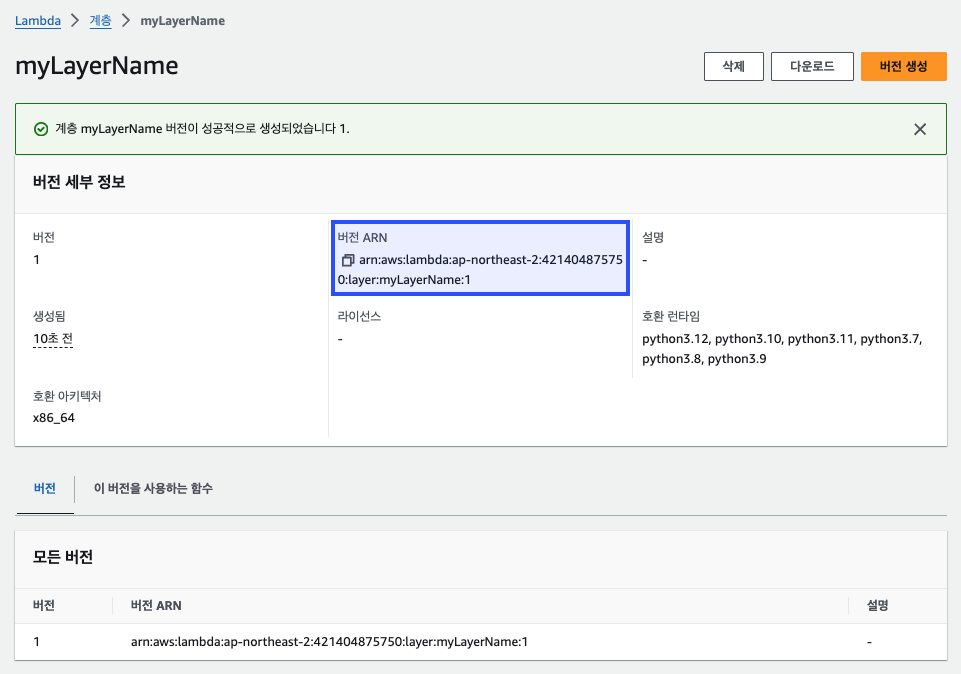
계층이 성공적으로 생성되면, 새로운 계층의 상세 페이지에서 "버전 ARN"을 확인할 수 있다. 이 ARN은 함수에 계층을 추가할 때 필요하다.
3.3 함수에 계층 추가
생성한 계층을 특정 Lambda 함수에 추가하는 방법을 안내한다.
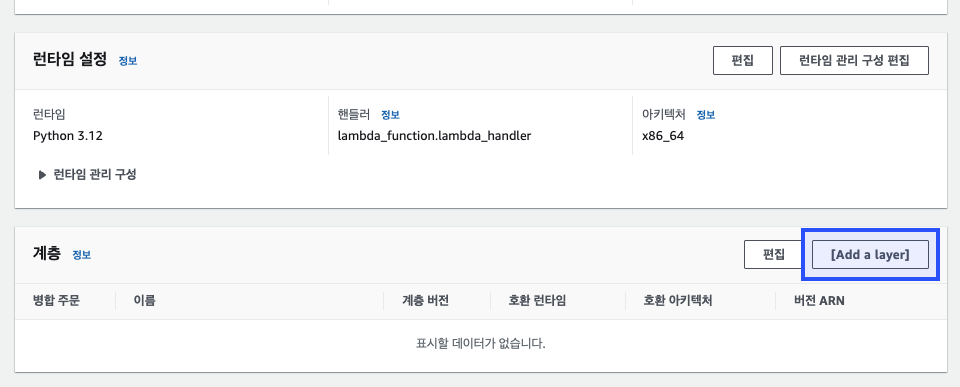
Lambda 함수의 "코드(Code)" 탭으로 이동한다. 여기서 "계층(Layers)" 섹션을 찾아 "[Add a layer]" 버튼을 클릭한다.
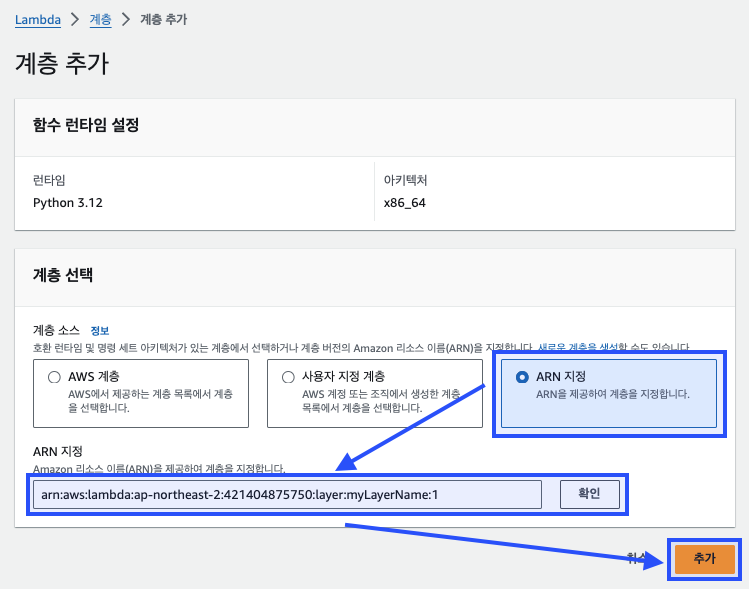
"ARN 지정" 옵션을 선택하고, 앞서 복사한 계층의 "버전 ARN"을 붙여넣는다. 이후 "확인" 버튼을 클릭하여 계층을 추가한다. "추가(Add)" 버튼을 통해 계층을 함수에 통합한다.
4. 판다스 사용 방법
Keith Rozario의 'Klayers'는 다양한 Python 패키지를 Lambda 계층으로 제공하는 프로젝트이다. 이를 활용하여 판다스를 Lambda 함수에 쉽게 추가할 수 있다.
4.1 layers 판다스 계층 ARN 찾기
먼저 Klayers 프로젝트의 GitHub 페이지(Klayers GitHub)를 방문한다.

"List of ARNs"에서 Lambda 런타임과 동일한 버전을 찾아 클릭한다.
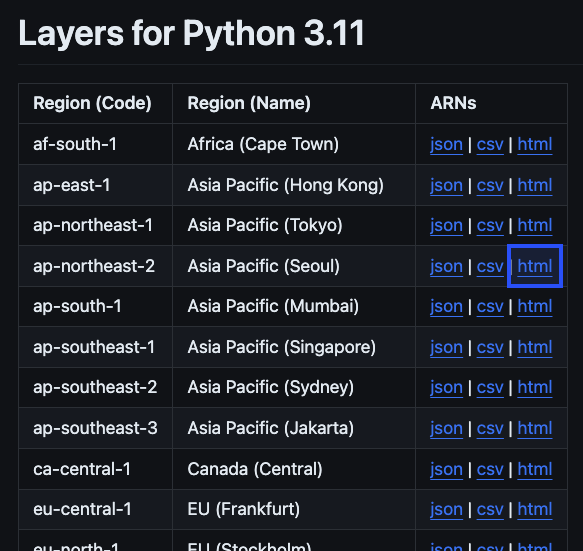
Lambda 해당 리전("ap-northeast-2")을 찾아 "html" URL을 클릭한다.
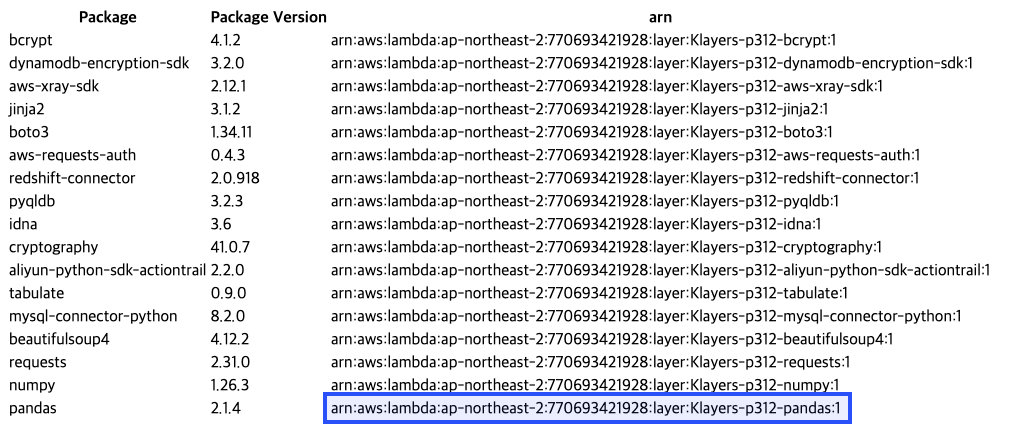
판다스(pandas) 패키지에 해당하는 arn(arn:aws:lambda:ap-northeast-2:770693421928:layer:Klayers-p312-pandas:1)을 찾아 복사한다.
4.2 함수에 판다스 계층 추가
Lambda 함수의 "코드(Code)" 탭으로 이동한다. 여기서 "계층(Layers)" 섹션을 찾아 "[Add a layer]" 버튼을 클릭한다.
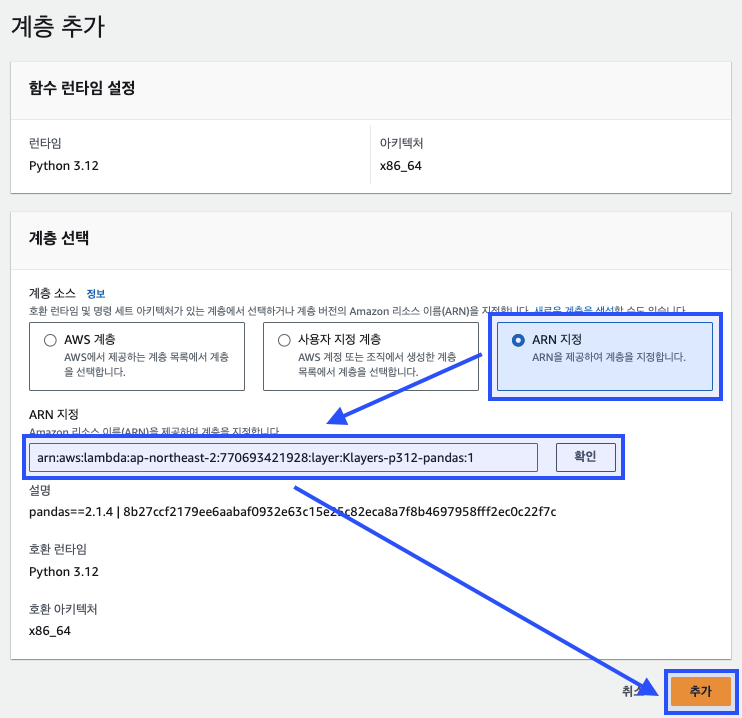
"ARN 지정" 옵션을 선택하고, Klayers 프로젝트에서 찾은 판다스 계층의 ARN을 입력한다. 이후 "확인" 버튼을 클릭하여 계층을 추가한다. "추가(Add)" 버튼을 통해 계층을 함수에 통합한다.
5. 테스트
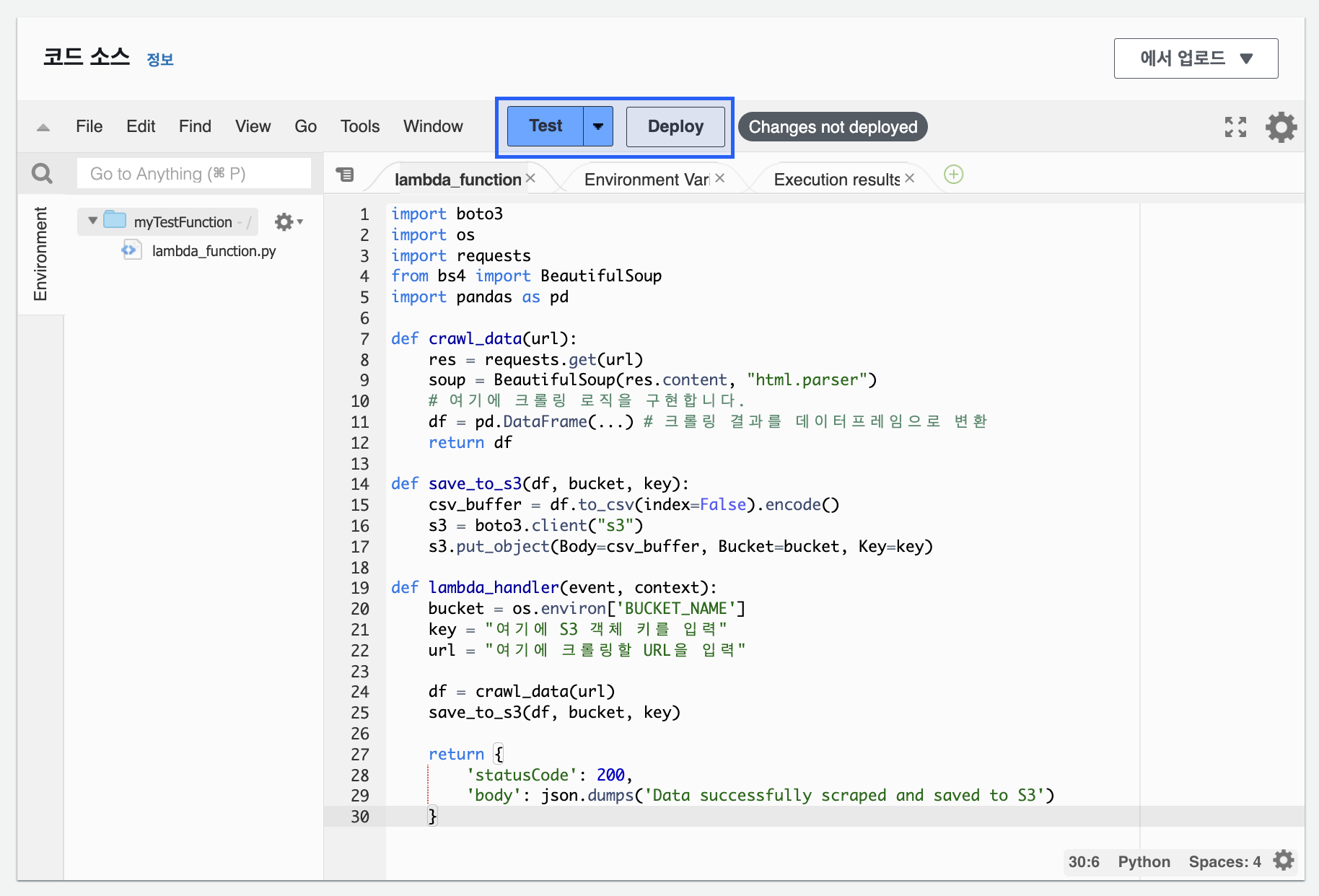
코드를 저장하고 "Deploy" 버튼을 클릭하여 배포한 후, "Test" 버튼을 클릭하여 함수를 테스트하면, 판다스에 대한 정상 작동을 확인할 수 있다.
6. 마무리
AWS Lambda의 계층(Layer) 기능을 활용하여 판다스(Pandas)를 비롯한 다양한 라이브러리를 Lambda 함수에 통합하는 방법에 대해 알아보았다. 이 과정은 코드의 재사용성을 높이고 라이브러리 관리를 더욱 효율적으로 만들어준다. 또한, Keith Rozario의 'Klayers' 프로젝트를 활용하는 방법을 통해, 필요한 Python 패키지를 Lambda 계층으로 손쉽게 추가할 수 있는 방법을 배웠다.
다음 아티클에서는 AWS Lambda를 활용한 스케줄링 기능에 대해 알아볼 예정이다. 이 부분에서는 AWS Lambda의 이벤트 기반 실행 방식을 활용하여, 정기적으로 작업을 수행하는 방법을 다룰 것이다.